






Microsoftの研究者たちは先日、たった3秒間の音声サンプルを与えることでにその人の声を再現することができるtext-to-speechのAIモデル「VALL-E」を発表した。
開発者によると、録音した本人の声を忠実に合成することができ、感情のトーンまで再現することができるという。また、高品質なテキスト読み上げアプリとして利用したり、録音したスピーチから台詞を変えた新たなスピーチを生成することも可能としている。
VALL-Eの音声生成モデル
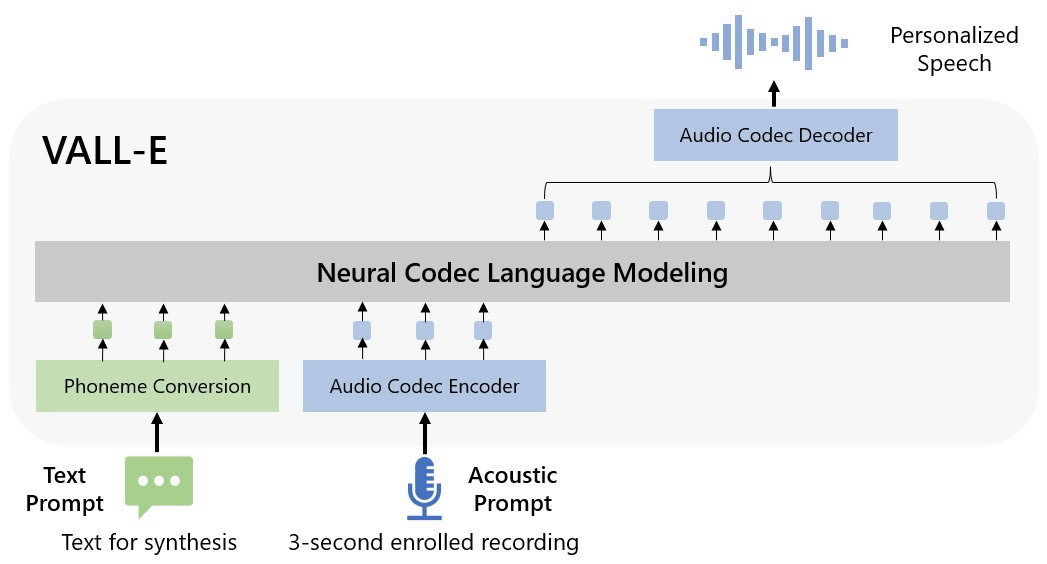
MicrosoftはVALL-Eを「neural codec language model」と呼び、Metaが2022年10月に発表したEnCodecの技術をベースに開発されており、音の波形から音声を合成するという一般的な方法ではなく、テキストと音響プロンプトから個別の音声コーデックコードを生成する。
これは、人の声を分析したデータをEnCodecによって「トークン」と呼ばれる要素に分解し、その声が3秒間の音声サンプル以外のフレーズを話した場合にどのように聞こえるかを学習データを使って一致させていくものだという。
この音声合成機能には、MetaのLibri-Lightという音声ライブラリが学習させており、Libri-Lightに収録されている7,000人以上の話し手による60,000時間の英語を話す音声が含まれている。そのライブラリからVALL-Eは3秒間のサンプル音声と近い音声を検索し、忠実に再現された音声を生成する。

現在、VALL-Eのデモページでは音声サンプルが数十種類公開されており、3秒間の音声サンプルとサンプルと同じ人物による実際の音声、従来の音声合成によって生成された音声、VALL-Eが生成した音声を聴き比べすることができます。
Speaker Prompt:3秒間の音声サンプル
Ground Truth:サンプル音声と同じ人物による音声
BaseLine:従来の音声合成によって生成された音声
VALL-E:VALL-Eが生成した音声
また、VALL-Eは音声認証などの偽装や特定の話し手へのなりすましなど、悪用されるリスクがあるため、MicrosoftはVAlL-Eのコードを提供していない。これを防ぐため、音声がVALL-Eによって合成されたものかどうかを識別する検出モデルを構築することは可能だと述べている。
VALL-E
▶︎Githubサンプル
参考記事
▶︎Microsoft’s new AI can simulate anyone’s voice with 3 seconds of audio
ARTICLE