





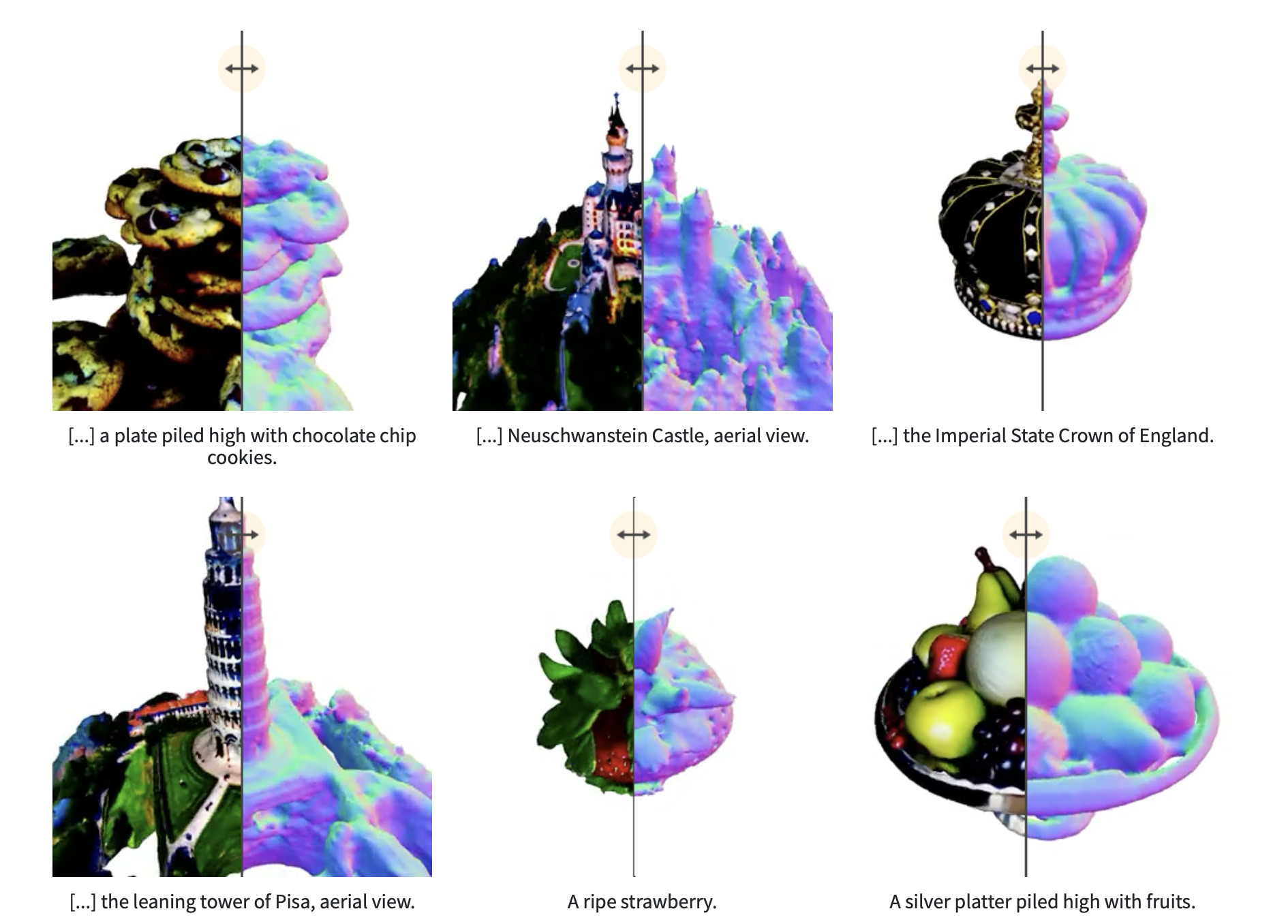
テキストベースによる画像生成AIや動画生成AIが飛躍的進歩を遂げている中、半導体メーカーであるNVIDIAは、入力したテキストを基に3Dモデルを生成するAI「Magic3D」を発表した。
これは入力したテキストプロンプトから高品質の3Dテクスチャメッシュモデルを作成でき、Google Researchが発表したText-to-3D AI「DreamFusion」に比べ、8倍の解像度、3Dモデル生成にかかる時間は半分程度だとしている。
3Dモデル生成プロセス
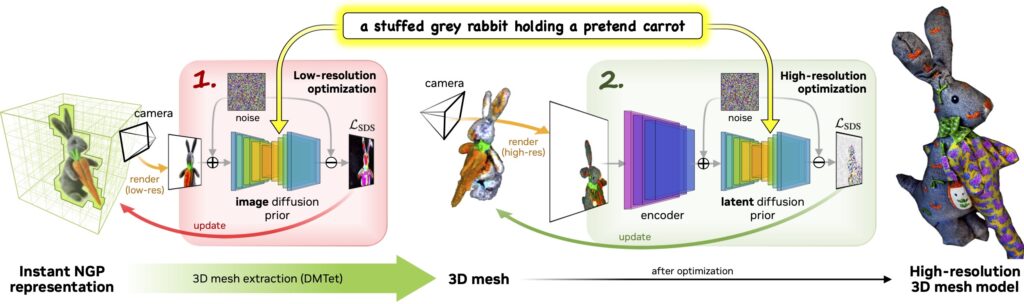
Magic3Dは3Dモデル生成に2段階のプロセスを使用しています。
最初に入力されたテキストを基に、NVIDIAが提供している画像生成AI「eDiffi」で2D画像を生成。その後、画像から空間を構築するNVIDIA Instant-NGPを使用し、2D画像から低解像度の3Dモデルを生成する。
次に、低解像度3Dモデルメッシュから高解像度の3Dモデルを合成する「DMTet AI」を使用し、高解像度の3Dモデルを抽出するという流れになっている。
Magic3Dが生成した3Dモデル

Magic3Dは生成された3Dモデルのテキストプロンプトを編集することで、3Dモデルを編集することができます。公開された動画内では「積み重なったパンケーキの上に座っている子うさぎ」を「積み重なったブロッコリーの上に座っているメタリックなうさぎ」「積み重なったチョコレートクッキーの上に座っているスフィンクス」と同じ構図で異なるモデルを生成している。

他にも、参考画像を入力することで、画像のスタイルと似た3Dモデルを生成することも可能となっている。
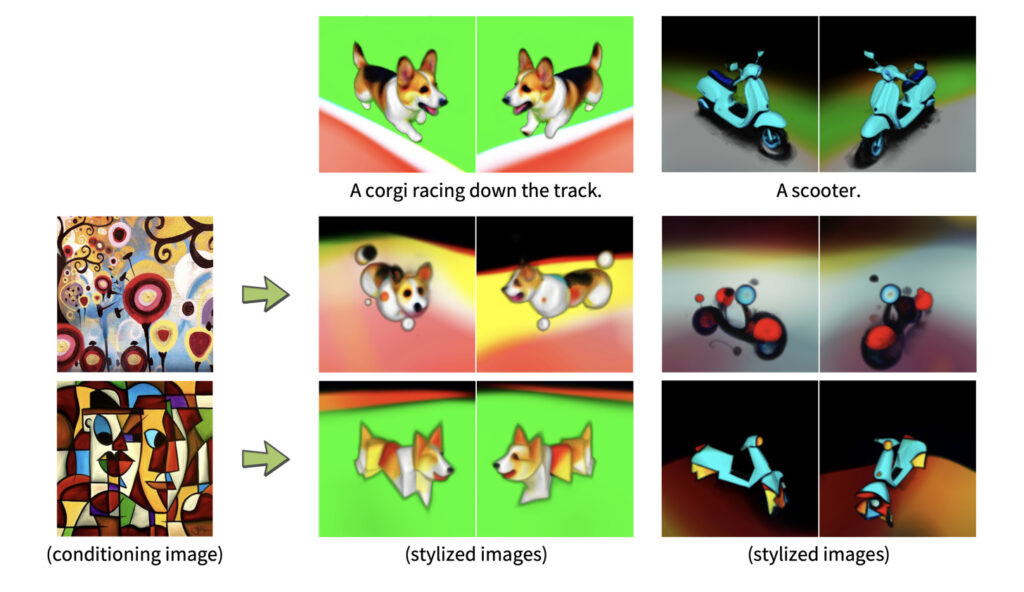
NVIDIAの研究チームは「Magic3Dの登場によって3Dモデルの合成を大衆化し、3Dコンテンツ制作において、大勢の人の創造性を開放することができると期待している」と述べている。
Magic3D: High-Resolution Text-to-3D Content Creation Webサイト
ARTICLE